

Quién iba a decir a los escritores que iban a ser los programadores del futuro en lugar de los ingenieros. Y es que, cuando hablamos de Inteligencia Artificial con algoritmos de Machine Learning, estamos haciendo referencia a una computadora, que por medio de un algoritmo creado por un ingeniero, aprende sola para resolver problemas de forma inteligente. Y es aquí donde llega la clave.
La gracia está en que, cuando queremos dotar a esos sistemas de inteligencia artificial de lo que llamamos servicios cognitivos, como son las capacidades cognitivas humanas, es decir, la vista, el reconocimiento de objetos, hablar, leer, comprender, traducir, explicar, responder a un humano, etcétera, debemos entrenar esos algoritmos de Machine Learning con los mismos datos que entrenamos a los humanos.
Por ejemplo, para que una Inteligencia Artificial aprenda a traducir debemos darle muchos textos escritos en los dos idiomas que queremos que traduzca, y el algoritmo de Machine Learning programado por el ingeniero hará que la Inteligencia Artificial aprenda, pero gracias a las traducciones hechas por muchos humanos antes. Y aprenderá bien o mal, con prejuicios, sesgos o defectos en función de cómo sea el algoritmo creado por el ingeniero y lo buenos o malos que sean los textos que le demos como datos de entrada.
Por supuesto, llevar a una inteligencia artificial que ha aprendido con libros a traducir frases sueltas sacadas de contexto puede generar los problemas de sesgos de género de los que ya os he hablado antes por aquí. En este caso en concreto, la culpa no es del humano traductor que hizo, con cuidado y esmero, la traducción del libro con el que la máquina aprendió a traducir después.
El problema se genera porque el humano traductor, para decidir si era un juez o una jueza —caso de uno de los ejemplos sesgados en la traducción— tuvo un libro entero para saber mucho más de ese personaje, y conocer si era hombre o mujer. Pero la inteligencia artificial no, y no puede extrapolar géneros a la hora de traducir frases sueltas, lo que lleva a que la culpa sea, en este caso, del ingeniero que eligió mal los datos para entrenar a la inteligencia artificial, o no supo diseñar un algoritmo con estos límites, o directamente que debía haber entrenado con otros datos diferentes su algoritmo.
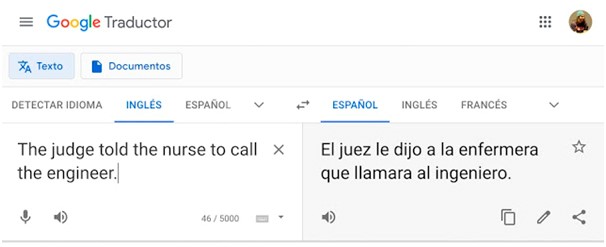
Traducción en Google con sesgo de género
Pero lo curioso de esto, querido lector y escritor, es que el humano traductor que generó los datos con los que aprendió esa inteligencia artificial no sabía, ni por asomo, que un día las decisiones que él tomó en su trabajo entrenarían a una inteligencia artificial que le sustituiría en muchas de sus facetas. Sin embargo, hoy ya lo sabemos. Cada dato que generamos en la red será utilizado para entrenar las inteligencias artificiales del futuro.
Así, los textos de nuestro querido y admirado Arturo Pérez-Reverte en El Capitán Alatriste sirvieron para entrenar a nuestro querido Maquet, aunque aún lejos de llegar a ser capaz de escribir como su profesor. Pero todos los textos que escribimos y volcamos en la red sirven para entrenar a una u otra inteligencia artificial, sea esta la que sea.
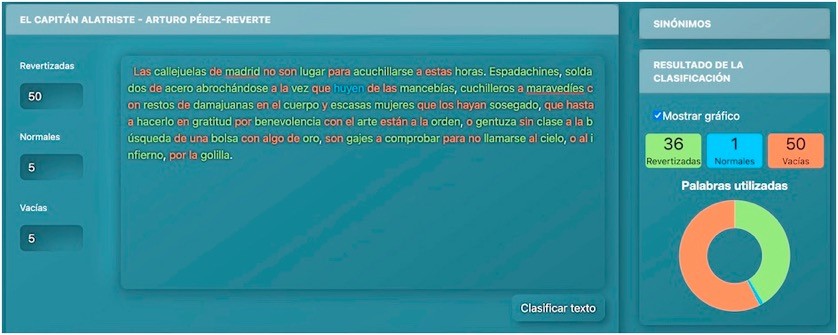
Texto de un imitador corregido por Maquet para simular ser de Arturo Pérez-Reverte.
Por ejemplo, los equipos de Microsoft crearon una inteligencia artificial para reconocer a famosos y así, sin yo saberlo, utilizando las fotos mías que había en la red, este servicio me convirtió en una celebridad, y con cualquier foto nueva me reconocía con facilidad, incluso medio disfrazándose. Como si fuera mi madre, que me reconoce de espaldas y de noche por como silbo.
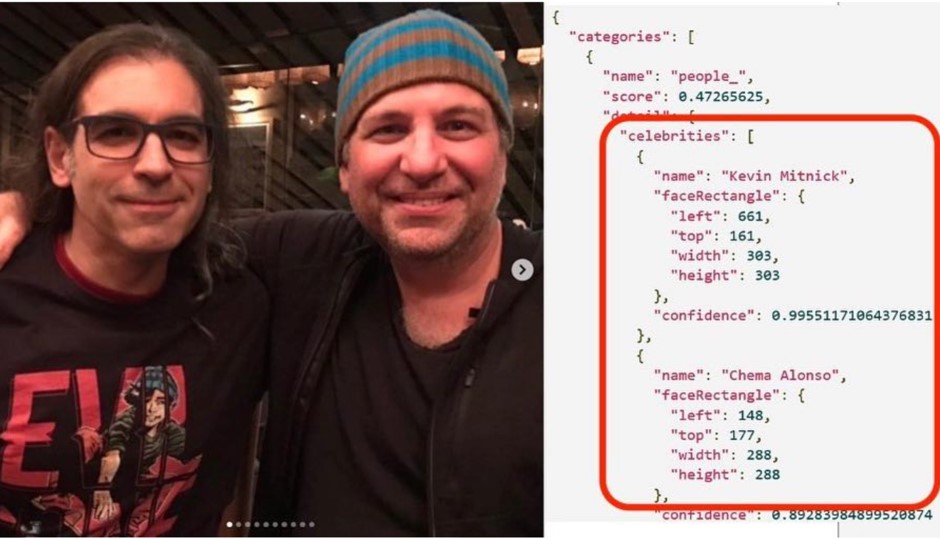
Kevin Mitnick y yo, reconocidos por la inteligencia artificial de reconocimiento de famosos.
Otro ejemplo famoso de datos utilizados para entrenar el servicio cognitivo de visión artificial y aprender a reconocer bien los objetos en tres dimensiones fue el famoso Mannequin Challenge, que seguro que muchos de vosotros habéis hecho, visto, o criticado, que de todo hay en la viña del Señor. Y como ese, el reto de la foto de los 10 años tuya, donde subías una foto tuya de hace diez años y otra en la actualidad, consiguiendo de esa forma entrenar a una inteligencia artificial a ser capaz de envejecer y rejuvenecer personas diez años de forma acertada y realista.
Esta última inteligencia artificial ha resultado ser una mina de oro en Hollywood, ya que en casi todas las películas hoy en día se usa en mayor o menor intensidad. ¿Qué hubiera sido de la famosa película El irlandés sin poder contar con esta tecnología que permite rejuvenecer personas? ¿Quién te iba a decir a ti, que subiste a la red esas fotografías, que estabas entrenando a una inteligencia artificial que ha hecho de oro a muchos en la industria del cine?
En el mundo de la programación hay también una auténtica revuelta, ya que GitHub, el servicio donde los programadores han publicado sus códigos, sus programas, sus algoritmos, etcétera, para compartir con la comunidad conocimiento, han sido usados para entrenar a una inteligencia artificial, que se llama Copilot y que comercializa ahora GitHub como un servicio de pago para que esta inteligencia artificial ayude a los nuevos programadores a sugerirles líneas de código.
Así que todos los datos que publiques en la red, incluido estos artículos que estamos subiendo a Zenda Libros, son indexados por Google o Bing, y utilizados para entrenar sus inteligencias artificiales basadas en datos masivos. Así, igual que comercializan servicios de traducción en forma de APIs que han sido entrenados con datos de los humanos traductores —sin ver ni un € por su trabajo de alimentar a la AI—, los artículos que publicas en tu blog, o en un periódico, o aquí, son indexados para entrenar a sus inteligencias artificiales y generar servicios.
Pero encima, si no tenemos cuidado, no solo estamos alimentando una inteligencia artificial que va a hacer lo mismo que nosotros —escribir los textos, como hicimos con Maquet— o aprender a razonar, o responder preguntas sobre textos con los servicios de comprensión lectora que ya tenemos, o cualquier otra cosa, sino que además somos responsables, sin saberlo, de que aprendan bien o mal.
Por ejemplo, si generamos artículos con sesgo de género por defecto, estaremos entrenando a una inteligencia artificial haciéndole pensar que un género es prioritario sobre otro. Es decir, supongamos que escribimos un artículo y el título es “Mejores tenistas de 2021”, pero luego solo hablamos de tenistas hombres. De esta forma tan simple habremos generado un artículo con sesgo de género por defecto, haciendo pensar que “tenistas” son hombres. Y está mal, porque estamos educando erróneamente a una inteligencia artificial.

Titular de un artículo con sesgo de género por defecto. Solo habla de hombres.
Y esto se transmite. Este artículo será indexado por Google o Bing. Y el sesgo de género creado en él hará que sus algoritmos de inteligencia artificial, usados para responder a las búsquedas de información de las personas, responda con sesgo de género también a las consultas.
Es decir, imaginemos que una persona quiere ver quiénes han sido, en el mundo del tenis, los mejores en el año 2021, sin importar si es hombre o mujer. Lo que obtendrá serán resultados de… hombres. Hay que navegar unos cuantos enlaces hasta llegar a la primera referencia a tenis femenino.
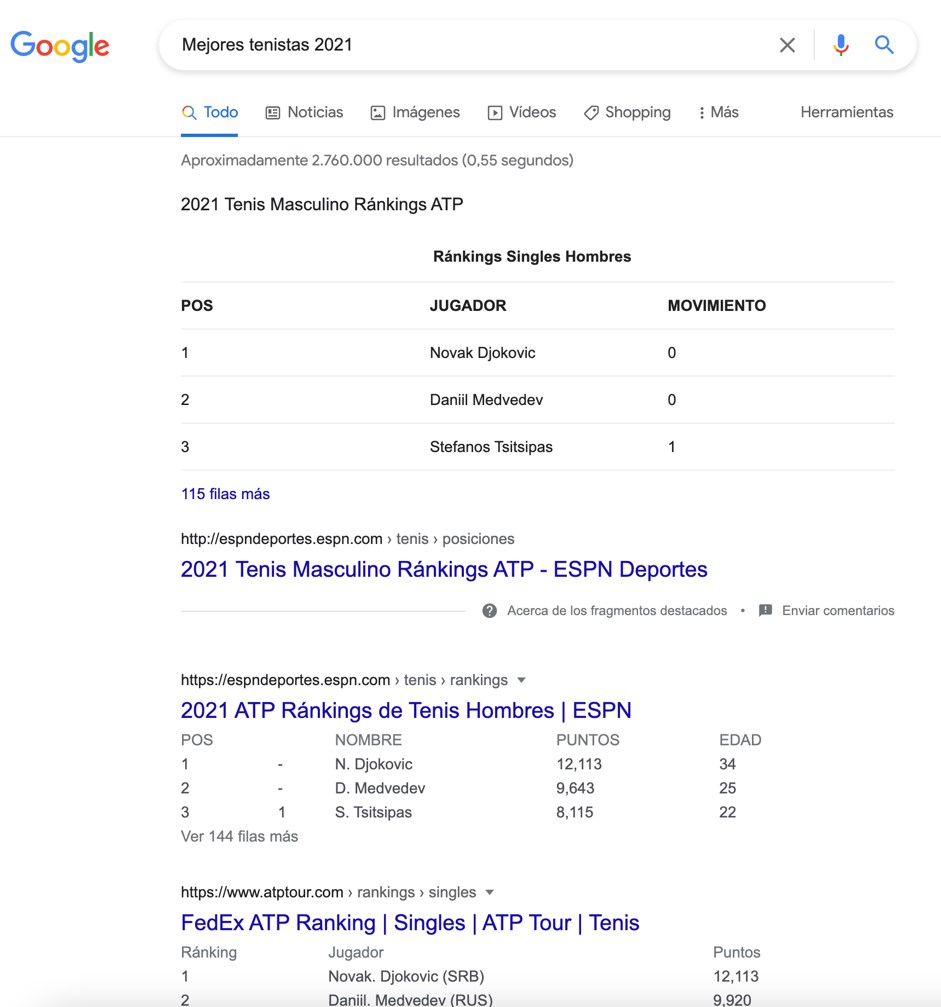
Sesgo de género por defecto en búsqueda de Google.
Por supuesto, la trampa del género por defecto no solo se genera porque el escritor del artículo publicado en un medio digital haya caído inadvertidamente en este. No, se genera también cada vez que alguien hace una búsqueda de sesgo de genero por defecto, ya que eso genera también datos en el buscador. Me explico:
Supongamos que queremos buscar los mejores tenistas masculinos de 2021 en Bing —por cambiar a otro motor de búsqueda— y hacemos una búsqueda con sesgo de género por defecto con un “Mejores tenistas 2021”. Es con sesgo de género porque nosotros sabemos que buscamos hombres, pero no se lo decimos al algoritmo del buscador. Y cuando nos muestran los resultados, vamos y hacemos clic en un resultado de hombres, en vez de hacer una nueva búsqueda.
Lo que sucede cuando elegimos un resultado en una búsqueda son sesgo de género y navegamos hacia él es que hemos entrenado a la inteligencia artificial con que esa cadena de búsqueda, que es la pregunta, se relaciona con ese enlace, que es la respuesta. Mientras que si hacemos una nueva búsqueda refinando los términos le enseñamos que ninguno de los resultados, para nosotros, es correcto.
Así que cada vez que escribes un artículo con un título con sesgo de género estás educando mal a las inteligencias artificiales que se entrenan con datos masivos. Cada vez que haces una búsqueda con sesgo de género estás entrenando mal a las inteligencias artificiales que se van a usar en tu vida en el futuro. Cada vez que pones un enlace en un documento con un hipervínculo en el que hay sesgo de género, mal educas a las inteligencias artificiales… y van a afectarte en tu presente y tu futuro porque todo, todo, todo, todo va a llevar inteligencia artificial en sus programas.
Y recuerda, a las inteligencias artificiales las educan los datos que les demos de comer, y no los algoritmos de Machine Learning que hacen los programadores, así que vosotros, escritores, publicadores de contenido, traductores, humanos que subís textos a vuestros blogs, sois también responsables de que nuestras inteligencias artificiales aprendan bien y no sean maleducadas o afecten negativamente a las personas.
También te puede interesar



-

Doce libros de abril
/abril 30, 2025/Los libros del mes en Zenda A lo largo de los últimos 30 días, hemos recogido artículos de obras de todos los géneros. Un mes más, en Zenda elegimos doce libros para resumir lo que ha pasado en las librerías a lo largo de las últimas semanas. ****** La flecha negra, de Robert Louis Stevenson «Cuatro flechas negras mi cinto tenía, cuatro por las penas que he sufrido, cuatro para otros tantos hombres que mis opresores malvados han sido». Con estas lacónicas y misteriosas palabras amenaza la hermandad de la Flecha Negra a sus víctimas. Situada en los primeros compases de…
-

De conquistas prohibidas
/abril 30, 2025/Varias ediciones las realizó para la Biblioteca Castro: en el año 2018, sobre Naufragios y Comentarios, Relación de la aventura por la Florida y el Río de la Plata de Alvar Núñez Cabeza de Vaca; en el 2019, Legazpi. El tornaviaje. Navegantes olvidados por el Pacífico norte. Entre 2017 y 2019, reeditó, en la editorial Athenaica, su trilogía Mitos y utopías del Descubrimiento, ya publicada por Alianza Editorial en 1989, tratando en el primer tomo de Colón y su tiempo, en el segundo de El Pacífico y en el tercero de El Dorado, y en 2020, publicó, de nuevo en…
-

6 poemas de Luciana Maxit
/abril 30, 2025/*** el génesis según martha argerich donde está tu tesoro, ahí está tu corazón mateo 6:2 no es cierto que martha Argerich creó el universo de la nada la tierra ya estaba ahí con sus estados nación y sus guerras mundiales ya existía buenos aires y juana heller llevaba puestos sus lentes de sol cuando en el parque un tordo se posó en su hombro y le dijo: juana, no temas concebirás en tu vientre a una hija será salvaje, su nombre martha y su reino no tendrá fin juana heller usó sus dedos para sacudir la ceniza del cigarro…
-

Y todo en un instante
/abril 30, 2025/Un accidente de tráfico, un semáforo en rojo, un coche a la fuga, una mujer herida y un inmigrante que rebusca en un contenedor. Y, por supuesto, un inspector, el inspector Tedesco, que deberá averiguar por qué intentaron atropellar a la desconocida y por qué apareció el cadáver del extranjero en el camión de basuras. En este making of Empar Fernández cuenta el origen de El instante en que se encienden las farolas (Alrevés). *** El instante en que se encienden las farolas tiene su origen en la observación de un fragmento muy breve de una discusión, apenas unas pocas…
Por eso comento tanto: para tratar de instruir.
IA=IA+1
x e y de la pizarra son imaginarios.
A cuenta de haber leído este artículo sobre IA, no sé si viene al caso pero siento curiosidad por tu perfil. Mi intención es hacerlo con respeto hacia la persona. Por un lado veo la parte de romanticismo informático y de trasgresión que representas y por otro veo al directivo atípico y super bien pagado, montado en la élite, dicho sin ánimo de ofender. Mi idea es que no observo justificación, no en tu caso, sino en todos los casos similares, ya que en este país no estamos creando nada, que yo sepa a nivel de lo que puedo informarme en los medios, que merezca la pena a nivel informático (me refiero a que facture, que exportemos, que vendamos por ahí fuera), salvo algunas excepciones como las de los videojuegos y algún antivirus (muy dignas, por cierto). Quiero decir, los gestores de bases de datos los tenemos que adquirir en el exterior; los sistemas operativos (tanto los micro como los macro), lo mismo; las grandes aplicaciones de gestión de negocio, igual de lo mismo; y creo que podría continuar. Esto hablando del soft; si hablamos del hard… ¿De qué nos sirven tantos gurus que, lo siento, no crean nada? En mi opinión son solamente gestores de herramientas y máquinas extranjeras. Sé que quizás no es culpa de las personas sino de la falta de confianza empresarial en las capacidades de las personas y, por consiguiente, en la falta de inversión en investigación tecnológica. Deberíamos hacer más en esto y no hace falta ser un país grande y poderoso para hacer esta investigación sino que países pequeños como Israel pueden ser punteros en estas tecnologías; claro que, hay que promover, alentar y financiar el talento.